 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMem: Context Management with A Decoupled Long-Context Model
May 29, 2026Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment. In this paper, we introduce CoMem, a novel framework that decouples memory management from the primary agent workflow, enabling these processes to execute in parallel. We propose a $k$-step-off asynchronous pipeline that overlaps the memory model's summarization with the agent's inference, effectively masking the latency of context processing. To ensure robustness under this asynchronous setting, we introduce a reward-driven training strategy that aligns the memory model to capture sufficient statistics for the agent's decision-making. Theoretical analysis confirms that CoMem offers a superior efficiency-effectiveness trade-off compared to coupled architectures. Our extensive experimental results on SWE-Bench-Verified show that CoMem provides 1.4x latency improvements upon vanilla long-context solutions while preserving most of the performance. Furthermore, we demonstrate that these latency gains scale favorably with increased system throughput, offering a modular path forward for the independent optimization of agent reasoning and memory compression.
GlucoFM: A Dual-Stream Foundation Model for Continuous Glucose Monitoring
May 29, 2026Continuous glucose monitoring (CGM) provides a dense view of daily metabolic physiology, yet existing generic time-series and CGM-specific foundation models often encode glucose traces as entangled single-stream sequences, leaving the distinct temporal structure of glycemic dynamics only implicitly modeled. We present GlucoFM, a lightweight CGM foundation model that aligns irregular recordings to a 24-hour chronological grid, preserves observation masks, and decomposes glucose dynamics into slow physiological state and transient event streams, capturing low-frequency glycemic baselines and short-term deviations that may reflect acute physiological responses or sensor artifacts. GlucoFM is pretrained on 109,066 hours of unlabeled CGM recordings from 477 subjects with two complementary objectives: masked contextual latent prediction over fused daily representations and temporal dynamics prediction over state and event streams. Across four diverse cohorts and seven clinical prediction tasks, GlucoFM achieves the strongest subject-disjoint linear-probing performance among evaluated baselines, improving average PR-AUC by 4.1 points over the best CGM-specific foundation model. Its gains are most pronounced on core metabolic outcomes, leading PR-AUC on all diabetes-risk and $β$-cell dysfunction tasks and on 3 of 4 insulin-resistance tasks. GlucoFM also achieves the best overall cross-dataset transfer performance and strong few-shot adaptation among evaluated methods, and consistent gains when aggregating multiple days for subject-level prediction, highlighting physiology-aware decomposition as an effective inductive bias for transferable CGM representation learning.
Towards a General Intelligence and Interface for Wearable Health Data
May 21, 2026While ubiquitous wearable sensors capture a wealth of behavioral and physiological information, effectively transforming these signals into personalized health insights is challenging. Specifically, converting low-level sensor data into representations capable of characterizing higher-level states is difficult due to high phenotypic diversity and variation in individual baseline health, physiology, and lifestyle factors. Moreover, collecting wearable data paired with health outcome annotations is laborious and expensive, and retrospective annotation remains practically unfeasible, contributing to a scarcity of data with high-quality labels. To overcome these limitations, we propose a foundation model for wearable health that is pretrained on more than one trillion minutes of unlabeled sensor signals drawn from a large cohort of five million participants. We demonstrate that the joint scaling of model capacity and pretraining data volume leads to systematic improvements in performance, as evaluated on a diverse set of 35 health prediction tasks, spanning cardiovascular, metabolic, sleep, and mental health, as well as lifestyle choices and demographic factors. We find that this population scale representation unlocks label-efficient few-shot learning and generative capabilities for robust daily metric estimation. To further leverage this learned representation, we deploy a classroom of LLM agents to autonomously search the space of downstream predictive heads built on the model embeddings, showing broad performance improvements that increase with LLM model capacity. Finally, we show how integrating these downstream predictors into a Personal Health Agent can support model responses that are more relevant, contextually aware, and safe, and we validate this via 1,860 ratings from a cohort of clinicians.
ChipMATE: Multi-Agent Training via Reinforcement Learning for Enhanced RTL Generation
May 13, 2026Existing API-based agentic systems for RTL code generation are fundamentally misaligned with industrial practice: they assume a golden testbench is available at generation time, rely on closed-source APIs incompatible with chip vendors' air-gapped security requirements, and cannot be trained on vendors' proprietary RTL codebases, leaving valuable internal data unused. Recent self-trained models address the deployment constraint but remain single-turn generators that overlook the critical role of verification in real industrial flows. To bridge these gaps, we present ChipMATE, the first self-trained multi-agent framework for RTL generation. Inspired by industrial practice where correctness emerges from cross-comparison between independently written RTL modules and reference models, ChipMATE pairs a Verilog agent with a Python reference-model agent that mutually verify each other's outputs without any golden oracle. We design a backtrack-based inference workflow to prevent error propagation across turns, and a two-stage training pipeline that first trains each agent individually to saturate its code-generation capability, then trains the team jointly to collaborate effectively. To support the training, we further build a hybrid data-generation framework that produces 64.4K high-quality reference model training samples. ChipMATE achieves 75.0\% and 80.1\% pass@1 on VerilogEval V2 with 4B and 9B base models, outperforming all existing self-trained models and even DeepSeek V4 with 1600B parameters. Our code and model weights are publicly available in https://github.com/zhongkaiyu/ChipMATE.
Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation
May 12, 2026Enabling Large Language Models (LLMs) to continuously improve from environmental interactions is a central challenge in post-training. While on-policy self-distillation offers a promising paradigm, existing methods predominantly treat environmental feedback as a passive conditioning signal. Consequently, they heavily rely on successful demonstrations and struggle to learn in rare-success regimes. To bridge this gap, we introduce Reflection-Enhanced Self-Distillation (RESD), a framework that transforms raw failure feedback into an active source of corrective supervision. Instead of passively appending feedback, RESD interprets failed trajectories by generating retrospective reflections to diagnose local errors, and curates a persistent global playbook to preserve reusable lessons across training steps. The enriched context enables the self-teacher to provide actionable token-level supervision even in the absence of successful rollouts. Empirical evaluations on multiple continual learning tasks demonstrate that RESD substantially outperforms standard self-distillation baselines. Furthermore, RESD achieves significantly faster early-stage improvement than GRPO with $8\times$ samples using only a single rollout per prompt, highlighting its superior interaction efficiency.
Wearable Foundation Models Should Go Beyond Static Encoders
Mar 20, 2026Wearable foundation models (WFMs), trained on large volumes of data collected by affordable, always-on devices, have demonstrated strong performance on short-term, well-defined health monitoring tasks, including activity recognition, fitness tracking, and cardiovascular signal assessment. However, most existing WFMs primarily map short temporal windows to predefined labels via static encoders, emphasizing retrospective prediction rather than reasoning over evolving personal history, context, and future risk trajectories. As a result, they are poorly suited for modeling chronic, progressive, or episodic health conditions that unfold over weeks, months or years. Hence, we argue that WFMs must move beyond static encoders and be explicitly designed for longitudinal, anticipatory health reasoning. We identify three foundational shifts required to enable this transition: (1) Structurally rich data, which goes beyond isolated datasets or outcome-conditioned collection to integrated multimodal, long-term personal trajectories, and contextual metadata, ideally supported by open and interoperable data ecosystems; (2) Longitudinal-aware multimodal modeling, which prioritizes long-context inference, temporal abstraction, and personalization over cross-sectional or population-level prediction; and (3) Agentic inference systems, which move beyond static prediction to support planning, decision-making, and clinically grounded intervention under uncertainty. Together, these shifts reframe wearable health monitoring from retrospective signal interpretation toward continuous, anticipatory, and human-aligned health support.
NC2C: Automated Convexification of Generic Non-Convex Optimization Problems
Jan 08, 2026Non-convex optimization problems are pervasive across mathematical programming, engineering design, and scientific computing, often posing intractable challenges for traditional solvers due to their complex objective functions and constrained landscapes. To address the inefficiency of manual convexification and the over-reliance on expert knowledge, we propose NC2C, an LLM-based end-to-end automated framework designed to transform generic non-convex optimization problems into solvable convex forms using large language models. NC2C leverages LLMs' mathematical reasoning capabilities to autonomously detect non-convex components, select optimal convexification strategies, and generate rigorous convex equivalents. The framework integrates symbolic reasoning, adaptive transformation techniques, and iterative validation, equipped with error correction loops and feasibility domain correction mechanisms to ensure the robustness and validity of transformed problems. Experimental results on a diverse dataset of 100 generic non-convex problems demonstrate that NC2C achieves an 89.3\% execution rate and a 76\% success rate in producing feasible, high-quality convex transformations. This outperforms baseline methods by a significant margin, highlighting NC2C's ability to leverage LLMs for automated non-convex to convex transformation, reduce expert dependency, and enable efficient deployment of convex solvers for previously intractable optimization tasks.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025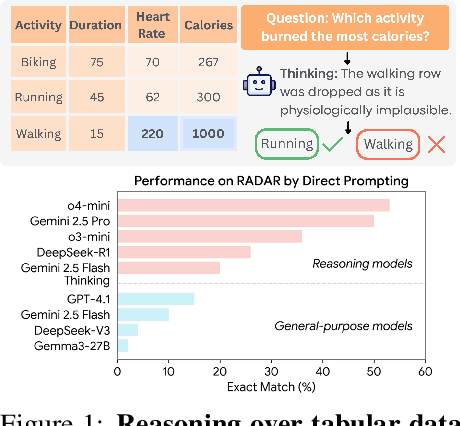
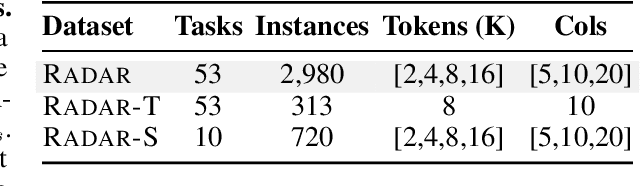
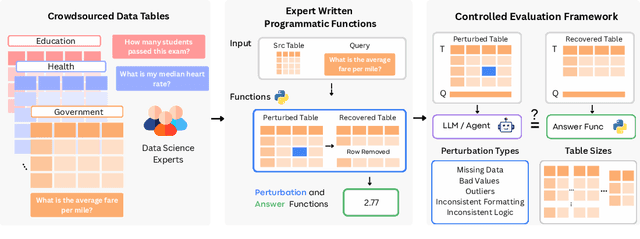
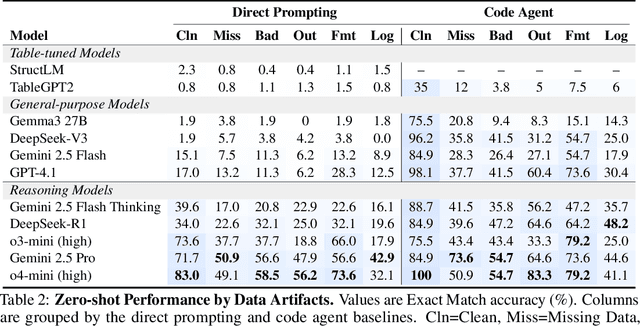
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.